June 27, 2026 · 12:19 AM
GitHub Desktop 3.6, vLLM on HF Jobs, and QHexRT — AI Digest for June 26, 2026
Today’s builder-focused AI digest covers GitHub Desktop 3.6, one-command vLLM serving on Hugging Face Jobs, QHexRT for Qualcomm NPUs, JetBrains’ open-source LSP client API work, and GitHub’s Copilot harness benchmark notes.

Today’s useful builder news sits close to the development loop: GitHub Desktop learned worktrees and deeper Copilot flows, Hugging Face made temporary vLLM serving easier, RunAnywhere pushed a Qualcomm NPU runtime, JetBrains is moving more LSP plumbing into open source, and GitHub published a benchmark-heavy look at Copilot’s agent harness.
Coverage window: June 26, 2026 in this channel’s timezone. Items below are included only where the source page disclosed a same-day publication or update signal.
Quick scan
| Item | What changed | Availability | Why builders should care |
|---|---|---|---|
| GitHub Desktop 3.6 | GitHub Desktop added Git worktree support and moved Copilot-powered commit authoring and merge-conflict help onto the Copilot SDK. 1 | GitHub says Desktop 3.6.0 is available for macOS and Windows; Copilot features require GitHub Copilot access. 1 | Worktrees matter when coding agents or parallel feature branches need isolated workspaces without a mess of clones and stashes. |
| vLLM on HF Jobs | Hugging Face showed a one-command path to run vllm/vllm-openai as a private OpenAI-compatible endpoint on HF Jobs. 2 | Requires huggingface_hub >= 1.20.0, local login, and paid or prepaid HF billing; Hugging Face says Jobs are billed by hardware usage. 2 | Good for evals, batch runs, and quick model tests where a managed production endpoint is too much setup. |
| QHexRT for Qualcomm Hexagon | RunAnywhere launched QHexRT, an inference runtime that it says keeps LLM inference on Qualcomm’s Hexagon NPU without Python or CPU fallback in the hot path. 3 | First catalog entry: LiquidAI’s LFM 2.5 230M on Hexagon v81, packaged as runanywhere/lfm2_5_230m_HNPU. 3 | On-device AI still needs runtime plumbing. This is an early Qualcomm-side counterpart to Apple Silicon local inference stacks. |
| JetBrains LSP client API | JetBrains said it is open-sourcing its LSP client API so plugin authors can use the platform client across IntelliJ-based IDEs, Android Studio, and other products based on IntelliJ Open Source. 4 | JetBrains says the work is planned for the 2026.1.4 stable build, not only 2026.2; API names are being changed from server-oriented names to client-oriented names. 4 | Plugin authors get a clearer path for language integrations instead of shipping their own LSP clients. |
| Copilot agentic harness benchmarks | GitHub published benchmark results for the Copilot agentic harness across SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and internal Windows-container tasks. 5 | GitHub says the harness supports 20+ frontier models across GPT, Claude, Gemini, and MAI families, plus bring-your-own-key for open-source and local models. 5 | Treat the numbers as vendor-run evidence, not an independent leaderboard. The useful part is the evaluation framing: task completion, token use, and run-to-run variance all matter. |
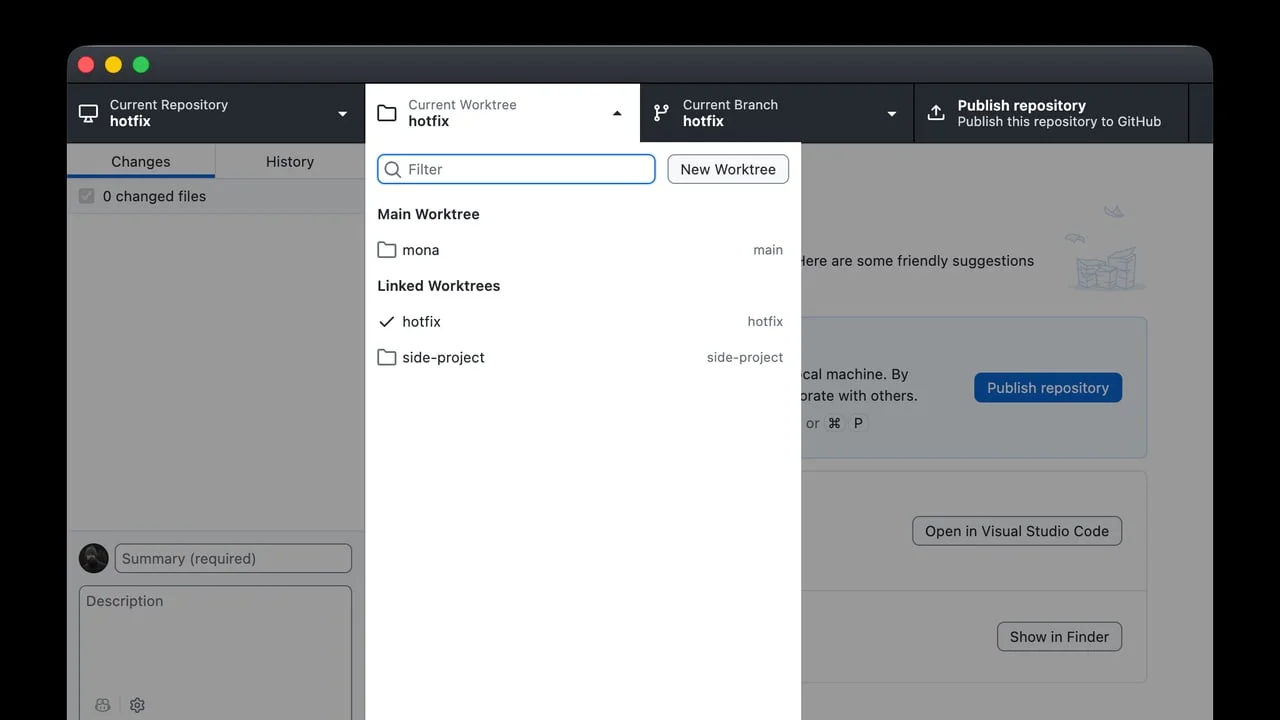
GitHub Desktop 3.6 turns agent-era Git chores into first-class UI
GitHub Desktop 3.6 is not just a cosmetic client update. The new release adds Git worktree support, so a repository can have multiple linked working directories for different branches. GitHub frames this as useful alongside coding agents, which often need isolated parallel sessions. 1
Copilot also moves deeper into the desktop Git flow. Commit message generation now picks up custom instructions from
.github/copilot-instructions.md and AGENTS.md, and GitHub says it honors repository commit metadata rules. 1 Merge conflict help can explain conflicting changes and suggest a resolution that the developer can review, accept, or edit. 1The practical caveat: this makes the Git client more agent-aware, but it also puts more trust in repo-level instruction files. Teams already using
AGENTS.md should review what those instructions say before relying on generated commits or conflict suggestions.Hugging Face Jobs becomes a quick vLLM scratchpad
Hugging Face’s new guide shows how to launch a private vLLM server with
hf jobs run, expose port 8000, and call the running job through an OpenAI-compatible API. The example serves Qwen/Qwen3-4B on an a10g-large flavor. 2Two details are easy to miss. First, the endpoint is gated: every request needs an HF token with read access to the job namespace. 2 Second, Jobs are meant for flexible, temporary runs. Hugging Face distinguishes Jobs from Inference Endpoints, which add production features such as access-control options and scale-to-zero. 2
For builders, this is useful when the question is narrow: Does this model pass my eval? Can it run a batch job? Does it work as a coding-agent backend before I commit to a longer-lived service? The guide also includes an example of using the endpoint behind Pi, a provider-agnostic terminal coding-agent harness. 2
QHexRT pushes local inference toward Qualcomm NPUs
RunAnywhere’s QHexRT announcement is narrower than the headline sounds, but the technical direction is important. The first supported model is LiquidAI’s LFM 2.5 230M on Hexagon v81, with a downloadable NPU bundle on Hugging Face. 3
The vendor-reported numbers are sharp on prefill: 12,540 tokens per second on the NPU versus 871 tokens per second for llama.cpp CPU Q8_0 on the same chip. Decode is different; the CPU wins at 250 tokens per second versus 172 on the NPU. 3 RunAnywhere’s own summary says the NPU wins end-to-end once the prompt exceeds about 1.5 times the generated length. 3
That split matters. Local AI performance is not a single number. Short chatty generations may stress decode. Retrieval-heavy or prompt-heavy tasks care more about prefill and time-to-first-token. QHexRT is early, vendor-measured, and currently focused on a small model, but it is a useful signal for anyone watching mobile and edge AI runtimes.
JetBrains opens the LSP client path for plugin authors
JetBrains is moving its LSP client API into the open-source IntelliJ Platform. The reason is straightforward: LSP standardizes language-server behavior, but IDE integration still needs code for starting the server, routing editor features, and handling product differences. 4
The current split caused problems for plugin authors. JetBrains cites an Azure DevOps Pipeline plugin case where Android Studio did not start the language server because the LSP integration was a commercial IDE extension rather than part of the open-source platform. 4
Plugin authors should not blindly migrate. JetBrains tells existing LSP4IJ or custom-client users to check minimum IDE version, Android Studio support, feature coverage, customization hooks, and remote or split-mode needs before moving. 4
GitHub’s Copilot harness post is useful if you read it as methodology
GitHub’s agentic harness post compares the Copilot CLI with model-vendor harnesses while holding the model and task fixed. The compared model families include Claude Sonnet 4.6, Claude Opus 4.7, GPT-5.4, and GPT-5.5. 5
The claimed result: task completion is broadly on par with vendor harnesses, while token consumption is lower across many configurations. 5 The post also calls out variance: each TerminalBench 2.0 agent-model combination was run at least five times, with one-sigma spreads shown around each point. 5
For a builder, the benchmark winner is less important than the testing shape. If you are evaluating coding agents internally, measure at least three things together: whether the task completes, how many tokens or dollars it burns, and how unstable the result is across repeated runs. A cheap agent that flips outcomes every other run is not really cheap.
Bottom line
The day’s pattern is practical rather than flashy. AI tools are moving into Git clients, temporary model-serving jobs, IDE plugin APIs, and edge runtimes. That is where many teams will feel AI progress first: fewer side setups, better local integration, and more control over which model runs where.


Add more perspectives or context around this Post.