
1/4
June 22, 2026 · 9:22 PM
Unlimited OCR:OCR 不再逐页失忆
新智元单篇文章图片笔记:百度开源 Unlimited OCR,用 R-SWA 固定 KV 缓存,把长文档 OCR 从逐页循环推向一次解析;图集拆解它的机制、跑分、40+ 页长文档能力和 32K prefill 边界。

Gallery
Unlimited OCR:长文档 OCR 的「软遗忘」方案
图集顺序:从为什么值得看 → R-SWA 怎么做 → 跑分信号 → 长文档能力与边界。
新智元在 2026-06-22 11:36 发布文章《刚刚,百度开源拿下全球第一!作者疑似 DeepSeek 出走大神》,报道百度开源 Unlimited OCR,并把它概括为「3B 参数、500M 激活、可一次解析 40 多页文档」的长文档 OCR 方案。1
百度官方 GitHub/Hugging Face 页面显示,Unlimited OCR 于 2026-06-22 发布,代码、模型权重与技术报告已公开;Hugging Face 页面标注模型大小为 3B params。23
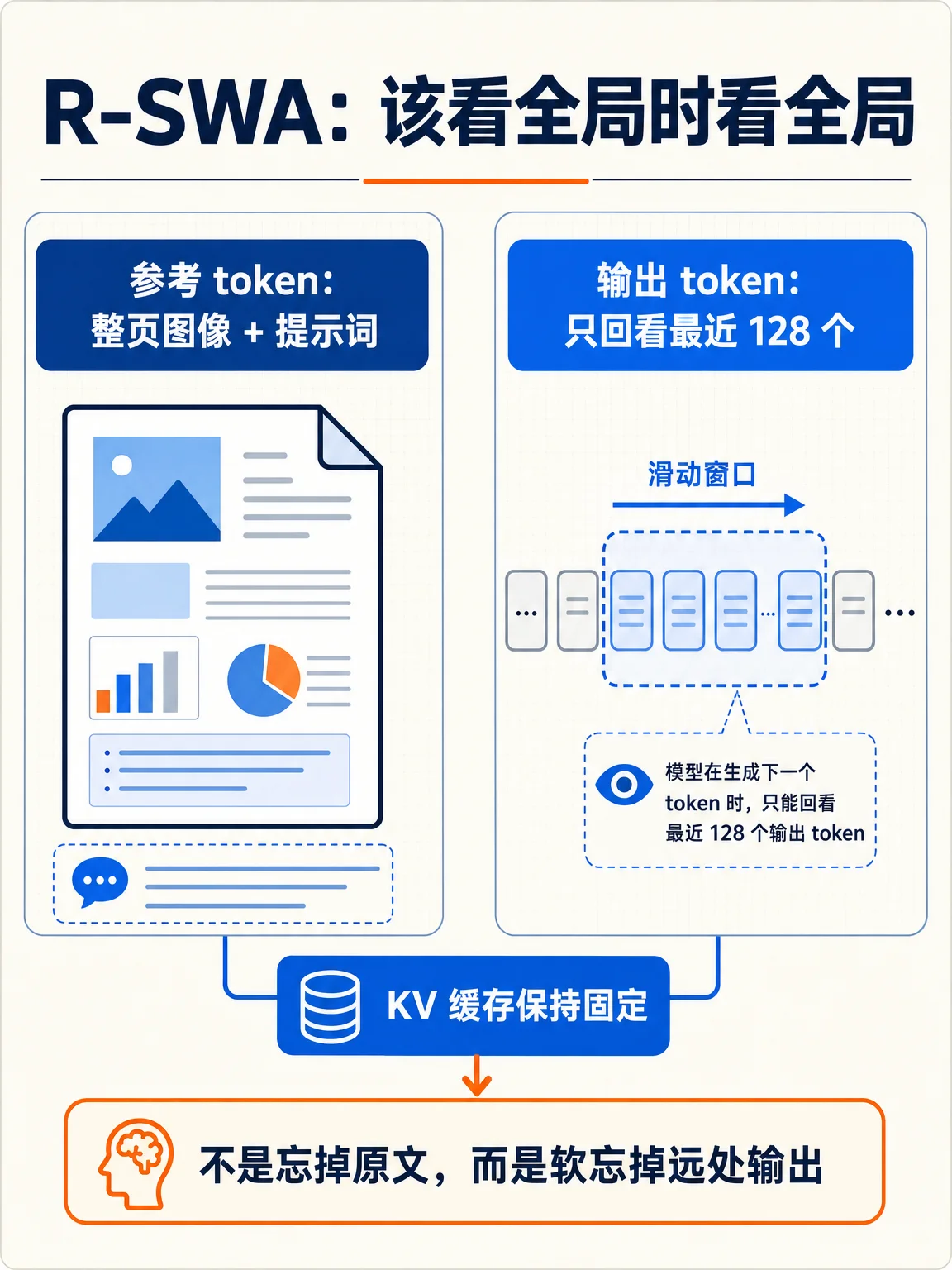
技术报告的核心不是把模型堆大,而是把 decoder 的标准注意力替换为 Reference Sliding Window Attention(R-SWA):每个生成 token 都能看见全部参考 token(视觉 token 与提示词),但输出侧只回看最近 n 个 token,默认 n=128,因此 KV cache 不再随输出长度线性增长。4
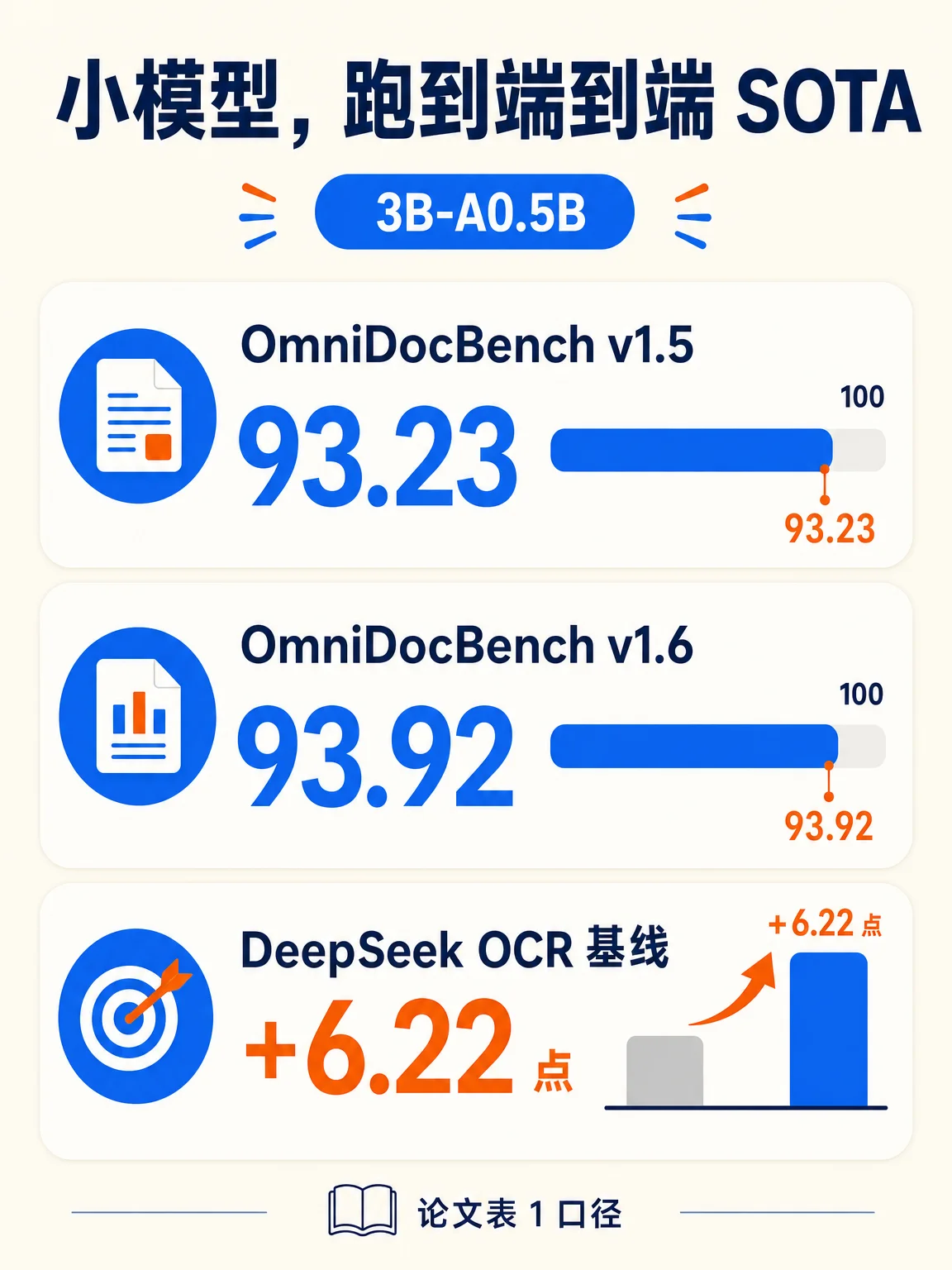
论文表 1 显示,Unlimited OCR 在 OmniDocBench v1.5 上 Overall 为 93.23,在 v1.6 上 Overall 为 93.92;相对 DeepSeek OCR 基线,v1.5 Overall 提升 6.22 点,Text Edit 从 0.073 降到 0.038,Formula CDM 从 83.37 升到 92.61,Table TEDS 从 84.97 升到 90.93。4
长文档测试里,论文表 3 给出 40+ 页场景 Distinct-35 为 96.90%、Edit Distance 为 0.1069;表 4 给出输出 6144 token 时 Unlimited OCR 理论 TPS 为 7847.71,DeepSeek OCR 为 5822.87,论文称约 35% 差距。4
需要保留边界:报告也明确说,有限上下文下还不能做到真正无限解析,32K 场景仍受 prefill 长度限制;后续方向是训练 128K 上下文,并构建 prefill pool,让模型学习自动取回 prefill KV chunk。4

Comments
Sign in to comment.